Sentiment Analysis on Healthcare Reviews
Google Collab Notebooks: Webscraping and Sentiment Analysis
Introduction to Our Tooling
Web scraping is the process of extracting data from websites. It involves using software tools to automatically collect data from web pages and store it in a structured format. Web scraping is used in a variety of applications, including data mining, price monitoring, and content aggregation.
For our purpose we’ll be using beautifulsoup for webscraping. Beautifulsoup is a Python library that is used for web scraping purposes. It is used to extract data from HTML and XML files. Beautifulsoup provides a simple way to navigate through the HTML and XML documents and extract the data you need. After our webscraping is accomplished we’ll move on to sentiment analysis.
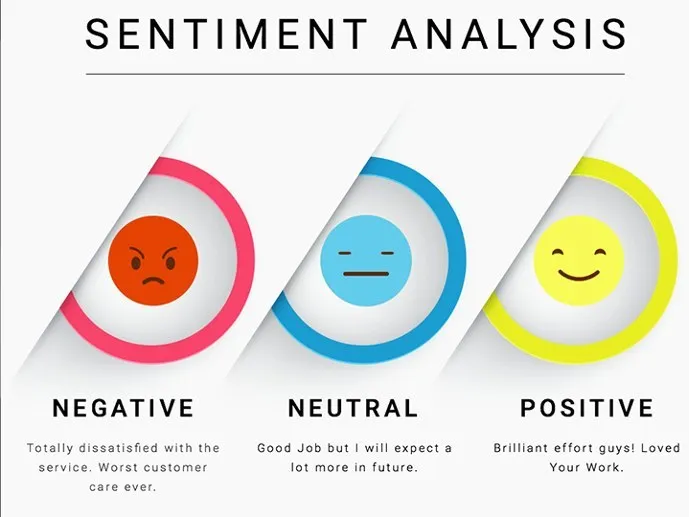
Sentiment analysis is the process of identifying and extracting subjective information from text data. It involves analyzing the sentiment of a piece of text to determine whether it is positive, negative, or neutral. Sentiment analysis is used in a variety of applications, including social media monitoring, customer feedback analysis, and market research. And for our purpose I’ll be using textblob.
Textblob provides an easy-to-use interface for performing sentiment analysis on text data. Textblob uses natural language processing techniques to determine the sentiment of a piece of text. It’s a popular tool for sentiment analysis because it is easy to use and provides accurate results. As an added bonus we’ll be using Scikit-LLM to test our sentiment analysis.
Large Language Models (LLMs) are part of natural language processing computer programs that use artificial neural networks to generate text. They are pattern completion programs that generate text by outputting the words most likely to come after the previous ones. LLMs learn these patterns from their training data, which includes a wide variety of content from the Internet and elsewhere, including works of fiction, conspiracy theories, propaganda, and so on. LLMs are used in a variety of applications such as AI chatbots and AI search engines.
We’ll be using Scikit-LLM to transform our reviews and then perform sentiment analysis on them. Scikit-LLM is a new library that allows us to perform vectorization, classification, and simplification using a large language model of our choice. You can check out the project here if you’re interested. Perhaps LLMs can be used more regularly in the future to improve sentiment analysis.
Defining Our Problem
Healthcare companies provide services to millions of Americans every year. Yet there seems to be a lack of communication on the part of their clients. For every business in America, we compare our options. Booking a flight, we compare our options. Why is it that when it comes to selecting a healthcare provider, we do not compare our options, and if we do it is through the tedious process of going plan to plan hoping the next plan is better than the previous one. Why are the providers themselves not accountable for the doctors in their service, the plan they provide, or the customer service experience.
In my search I have found websites to compare doctors and plans, but few websites even bother to discuss the posibility that the provider is important too. To remedy this I found a website that lists reviews for healthcare providers (which was rather difficult to locate) and webscraped the data to begin a sentiment analysis on healthcare providers.
Webscraping
As always we begin by installing and loading libraries.
#instillations
!pip install requests beautifulsoup4#libraries
import pandas as pd
import requests
from datetime import datetime
from bs4 import BeautifulSoup
import string
from google.colab import files
#quality of life
pd.set_option('display.max_colwidth', None)
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)Once we’ve completed loading our libraries its a good idea to get our requirements downloaded.
#requirements.txt
!pip freeze > requirements.txt
#download txt
files.download('requirements.txt')Let’s jump right into it and get some webscraping done. Here at our website you can see a number of companies and clicking into these companies allows us to see a number of reviews on different pages. We’ll create a for loop to go through our different companies, another for loop to cycle through the pages, and a final for loop to gather all the reviews on each page. Let’s also grab the date and company names while we’re here.
#creating of dataframe
reviews_df= pd.DataFrame({'CompanyName': [], 'Review': [], 'Date': []})
#url with multiple possible companies and parse
primary_url = "https://www.consumeraffairs.com/insurance/health.html#best-rated-all"
primary_response = requests.get(primary_url)
primary_soup = BeautifulSoup(primary_response.content, "html.parser")
#for loop going through company urls in HTML
for i in primary_soup.find_all("div", {"class": "brd-card__tit-innr"}):
link = i.find("a")["href"]
if link[:5] == 'https': #only selects links where reviews are present
#print(link) #verify correct company selection
#refresh url with base review page 1 and parse
url = link+'?page=1#sort=recent&filter=none'
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
#find last page for reviews and create a variable
last_page = soup.find_all("div", {'class': 'js-paginator-data'})[0]['data-last-page']#why an index is part of this i'll never know
#for loop using last page as max iteration
for j in range(int(last_page)+1):
#ensure we dont use page 0 since it does not exist then parse
if j != 0:
#print(url.replace('1',str(j))) #verify pages are being shifted through
response = requests.get(url.replace('1',str(j)))
soup = BeautifulSoup(response.content, 'html.parser')
reviews = soup.find_all('div', {'class': 'rvw js-rvw'})
#for loop going through all reviews and putting them in dataframe
for review in reviews:
review_text = review.find('div', {'class': 'rvw-bd'}).text.strip()
review_text = review_text.replace('Original review:', '')
review_text = review_text.replace('Read full review', '')
review_text = review_text.replace('Resolution response: ', '')
review_text = review_text.replace('\n', '')
date_string = review_text.split(", ",1)[0]+', '+(review_text.split(", ",1)[1])[:4]
date_string = date_string.replace('Sept.', 'September'
).replace('Oct.', 'October'
).replace('Jan.', 'January'
).replace('Aug.', 'August'
).replace('Dec.', 'December'
).replace('Feb.', 'February'
).replace('Nov.', 'November')
review_text = review_text.split(", ",1)[1]
#initally tried a "try except" clause but datetime was not happy with that
#opted for the kiss methodology of coding
reviews_df = pd.concat(
[reviews_df, pd.DataFrame(
{'CompanyName': link[42:-5].strip(), 'Review': [review_text[4:].strip()], 'Date': [datetime.strptime(
date_string.strip(), '%B %d, %Y')]})], ignore_index = True)Let’s check our data out and preview it.
#columns and shape
reviews_df.info()#first few records
reviews_df.head()Now that we have our data its time to get it cleaned up. Our webscraping process did a decent job, but lets see it can be improved.
Data Cleaning
#initally thought about a for loop but at the end of the day it would still require me to write everything out
#kiss strikes again
reviews_df_nc= pd.DataFrame(reviews_df['CompanyName'].replace('humana-right-source-rx', 'humana' #nc for name change
).replace('oxford-health-plans', 'united_health_care' #oxford is owned by united
).replace('cigna_tel_drug', 'cigna_health'
).replace('bluecross_fl','bluecross' #lets unify all the bluecross
).replace('bluecross_ca', 'bluecross'
).replace('bluecross_il', 'bluecross'
).replace('bluecross_nj', 'bluecross'
).replace('bluecross_ny', 'bluecross'
).replace('united_am', 'united_american'
).replace('amer_rep', 'american_republic'
).replace('golden_rule', 'united_health_care' #golden rule is owned by united
).replace('ihc-health-solutions', 'ihc_health_solutions')).join(reviews_df['Review']).join(reviews_df['Date'])
reviews_df_nc['CompanyName'].value_counts()Now that we’ve cleaned up the names and combined the subsidiaries, we can focus on the reviews themselves.
#clean the data of non-ascii characters
all_chars = list(string.ascii_letters + string.digits + string.punctuation + '“’”‘ ') #a bit of trial and error to get this part right
for i in range(len(reviews_df_nc)):
clean_review = ''
for j in range(len(reviews_df_nc.loc[i, 'Review'])): #this part was kinda annoying to come up with, chatgpt got me though
if reviews_df_nc.loc[i, 'Review'][j] in all_chars:
clean_review += reviews_df_nc.loc[i, 'Review'][j]
reviews_df_nc.loc[i, 'Review'] = clean_review.strip()
reviews_df_clean = reviews_df_nc
reviews_df_clean.head()Let’s run some standard checks to ensure all is well.
#checking for nulls
missing_data = reviews_df_clean.isnull()
#prints no missing values for all columns unless nulls exist
for column in missing_data.columns.values.tolist():
if missing_data[column].sum() != 0:
print(column)
print (missing_data[column].sum())
print("")
else:
print(column,"has no missing values\n")#removing duplicate values
reviews_df_clean = reviews_df_clean.drop_duplicates(keep='first')
reviews_df_clean.info()Our process was solid and produced no data errors nor duplication. Let’s add some more features to our dataframe.
Additional Features
#drop individual record
reviews_df_clean = reviews_df_clean[reviews_df_clean.CompanyName != 'medicareenrollmentcom']
reviews_df_clean.head()#create ownership type(private, public, non-profit)
ownership_lst = []
for i in reviews_df_clean['CompanyName']:
match i:
case 'united_health_care':
ownership_lst.append('Public')
case 'humana':
ownership_lst.append('Public')
case 'cigna_health':
ownership_lst.append('Public')
case 'aetna_health':
ownership_lst.append('Public')
case 'wellcare':
ownership_lst.append('Public')
case 'health_net':
ownership_lst.append('Public')
case 'united_american':
ownership_lst.append('Public')
case 'kaiser':
ownership_lst.append('Private')
case 'bluecross':
ownership_lst.append('Private')
case 'anthem':
ownership_lst.append('Private')
case 'amerihealth':
ownership_lst.append('Private')
case 'american_republic':
ownership_lst.append('Private')
case 'aarp_health':
ownership_lst.append('Non-Profit')
case 'carefirst':
ownership_lst.append('Non-Profit')
case 'ihc_health_solutions':
ownership_lst.append('Non-Profit')
case 'highmark':
ownership_lst.append('Non-Profit')
case _:
pass
len(ownership_lst)#add ownership type
reviews_df_clean['OwnershipType'] = ownership_lst#new column
reviews_df_clean.info()#preview with new column
reviews_df_clean.head()We’ve gone ahead and manually search and found info about our companies. We’ll be using this later in our analysis to form conclusions on the possible ownership types and how they relate to consumer opinion.
Let’s also add a couple more features that directly relate to our reviews.
#add review length as column
review_len = []
for i in range(len(reviews_df_clean)):
review_len.append(len(reviews_df_clean.iloc[i, 1]))
reviews_df_clean['ReviewLen'] = review_len
reviews_df_clean.info()# add sentence length as column
punc_count = reviews_df_clean.iloc[i, 1].count('.')+reviews_df_clean.iloc[i, 1].count('?')+reviews_df_clean.iloc[i, 1].count('!')
avg_sentence_len = []
for i in range(len(reviews_df_clean)):
if (punc_count) != 0:
avg_sentence_len.append(round(review_len[i]/punc_count,2))
else:
avg_sentence_len.append()
reviews_df_clean['AvgSentenceLen'] = avg_sentence_len
reviews_df_clean.info()Let’s download our dataframe and host it on Git.
#create csv
reviews_df_clean.to_csv('reviews.csv', index=False)
#download csv
files.download('reviews.csv')In a few code chunks we’ve scraped our website for data. Properly labeled and cleaned it, and added a number of columns to assist our analysis.
Now we can get started.
Loading and Processing
In our new environment we’ll begin by installing and loading same as before.
!pip install scikit-llm#libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from textblob import TextBlob
from wordcloud import WordCloud
from skllm.config import SKLLMConfig
from skllm.preprocessing import GPTSummarizer
from google.colab import files
#quality of life
pd.set_option('display.max_colwidth', None)
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
sns.set(rc={'figure.figsize':(11.7,8.27)})We’ll also be downloading our requirements and inputting our OpenAI API key and Org ID.
#requirements.txt
!pip freeze > requirements.txt#api key and org id
SKLLMConfig.set_openai_key("OPENAI-API-KEY")
SKLLMConfig.set_openai_org("OPENAI-ORG-ID")Now let’s load our data and ensure all is still good with our data.
#load the data
reviews_df = pd.read_csv("https://raw.githubusercontent.com/AlvarezJoe/Datasets/main/reviews.csv")
reviews_llm45_df = pd.read_csv("https://raw.githubusercontent.com/AlvarezJoe/Datasets/main/reviews_llm45.csv")
reviews_llm90_df = pd.read_csv("https://raw.githubusercontent.com/AlvarezJoe/Datasets/main/reviews_llm90.csv")#display info
reviews_df.info()#checking for nulls
missing_data = reviews_df.isnull()
#prints no missing values for all columns unless nulls exist
for column in missing_data.columns.values.tolist():
if missing_data[column].sum() != 0:
print(column, "-", missing_data[column].sum(), "missing values")
print("")
else:
print(column,"has no missing values\n")We quickly found 2 missing reviews. It seems somehow they evaded our data cleaning previously. This is why it’s important to always check your data!
#drop nulls
reviews_df = reviews_df.dropna()
reviews_df.info()Now that all is ready we’ll begin by creating our LLM reviews. If you paid attention you’ll notice we already made these and are loading them from Git. To prevent rerunning this long process and reusing my API key, I’ve gone ahead and loaded them into Git to load via csv. I’ll still include the code for creating these just know if you are following along the data is freely being hosted in my Git.
Creating Our Scikit-LLM Reviews
#checking the length of reviews using words
reviews_df['WordsPerReview'] = reviews_df['Review'].str.split().apply(len)
reviews_df['WordsPerReview'].head()#average words per review
reviews_df['WordsPerReview'].mean()Since we identified 180 words as the average length of a review, I’ll stick with the creation of these reviews using halving. I’ll also stick to 500 reviews. To create all 10,000ish reviews in these models would be almost 6 hours each!
#different metrics for model
gpts90 = GPTSummarizer(openai_model="gpt-3.5-turbo", max_words=90)
gpts45 = GPTSummarizer(openai_model="gpt-3.5-turbo", max_words=45)#only 500 reviews
rev = reviews_df['Review'].values[:500]#create llm90
reviews_llm90_df = pd.DataFrame(gpts90.fit_transform(rev), columns = ['Review'])
reviews_llm90_df.head()#create llm45
reviews_llm45_df = pd.DataFrame(gpts45.fit_transform(rev), columns = ['Review'])
reviews_llm45_df.head()They look awesome! Now let’s export these so we don’t have to keep remaking these every time we use this notebook.
#create csv for llm90
reviews_llm90_df.to_csv('reviews_llm90.csv', index=False)#create csv for llm45
reviews_llm45_df.to_csv('reviews_llm45.csv', index=False)Let’s also download and upload them into Git.
#download both
files.download('reviews_llm90.csv')
files.download('reviews_llm45.csv')Using Textblob
We’ll begin by creating a polarity and subjectivity column in our dataframes.
#create subjective and polarity columns
def getSubjectivity(text):
return TextBlob(text).sentiment.subjectivity#get polarity with a function
def getPolarity(text):
return TextBlob(text).sentiment.polarity#create subjective and polarity columns
reviews_df['Subjectivity'] = reviews_df['Review'].apply(getSubjectivity)
reviews_df['Polarity'] = reviews_df['Review'].apply(getPolarity)#create subjective and polarity columns for llm90
reviews_llm90_df['Subjectivity'] = reviews_llm90_df['Review'].apply(getSubjectivity)
reviews_llm90_df['Polarity'] = reviews_llm90_df['Review'].apply(getPolarity)#create subjective and polarity columns for llm45
reviews_llm45_df['Subjectivity'] = reviews_llm45_df['Review'].apply(getSubjectivity)
reviews_llm45_df['Polarity'] = reviews_llm45_df['Review'].apply(getPolarity)Now let’s boil down our polarity into a positive, negative, and neutral column called analysis.
#create a function to check negative, neutral and positive analysis
def getAnalysis(score):
if score<-.05:
return 'Negative'
elif score>.05:
return 'Positive'
else:
return 'Neutral'#create analysis column
reviews_df['Analysis'] = reviews_df['Polarity'].apply(getAnalysis)#create analysis column for llm90
reviews_llm90_df['Analysis'] = reviews_llm90_df['Polarity'].apply(getAnalysis)#create analysis column for llm45
reviews_llm45_df['Analysis'] = reviews_llm45_df['Polarity'].apply(getAnalysis)We can finally get started on sentiment analysis.
Sentiment Analysis
Largely we can break up our sentiment analysis into several parts. We’ll begin with a correlation matrix, analyze ownership type, examine how months and even years may play a part, analyze each company individually, and then create some word clouds to inspect all our reviews together.
If you’d like to see how these visualization are created, I encourage you to take a look at the google collab. It’s always impressive how complex visualizations are made so easily using matplotlib and sns.
Correlation Matrix
I’d like to note that we have a limited amount of quantitative columns in our data frame. So while we may not solve everything using a correlation matrix in this dataset. It helps to always inspect correlation between your dataset’s quantitative columns.

For the most part the length of reviews has little to no influence on our sentiment analysis. Let’s explore other avenues.
Ownership Type

It seems that the vast majority of our reviews are about publicly traded companies. Non-profits are far and few between. That might bias our data.
Either way it is somewhat uplifting to see that most reviews are positive.

Non-profits and publicly traded companies are both receiving a higher ratio of positive reviews. Perhaps there is only a few “bad apples” ruining the batch. We’ll check that out later.
Date


It seems that a large change occurred around 2018 and 2021. That definitely requires more attention. Remember this an increase of public opinion for all healthcare companies.
Unfortunately we are now experiencing a sharp decline in sentiment. The reason for the rise and fall of this should be investigated. Did market conditions shift? Did a shift in law cause newfound confidence in these companies?
The earlier years had a lot of variability in data. Perhaps this has to do with less available data.

Seems I was correct. Data is spotty before 2010 and begins falling off again after 2020. This definitely requires more attention.
Company Name
#create a dataframe to better highlight the quality of each of there companies
avg_polarity = pd.DataFrame(reviews_df.groupby('CompanyName')['Polarity'].mean())
total_count = reviews_df['CompanyName'].value_counts()
company_type = reviews_df.groupby('CompanyName')['OwnershipType'].unique()
company_analysis = avg_polarity
company_analysis['TotalCount'] = total_count
company_analysis['OwnershipType'] = company_type
company_analysis.sort_values('Polarity', ascending=False)
When we look at this dataframe we can see that all our non-profits have a good reputation among their customers. It seems wellcare, amerihealth, and healthnet are poorly reviewed. Kaiser is in an interesting position though, despite being a larger private company they still have fairly good reviews comparatively.


Within my collab you can see a more focused perspective company by company. Lastly for our analysis we’ll be touching on the reviews themselves via word clouds.
Word Clouds

For the most part our word clouds are similar among negative, neutral, and positive reviews. Most importantly is that customers all have pay, doctor, claim, insurance, called, coverage, and time. This is an obvious reflection of their values when it comes to healthcare companies.
Sentiment Analysis Conclusions
For the most part finding the perfect company does not exist, but what we can do is avoid companies with a bad reputation. Our problem is simple: without a centralized website, is it difficult to come to conclusions on what companies provide excellent care, insurance, and customer service. Until that problem is satisfied, webscraping and sentiment analysis are our best bet on determining this. I may have only have scraped one website, but with enough work anyone can put together even more data on these companies. Ultimately despite the amount of data we collected there are some general recommendations that can be made when deciding a provider.
Just because a company is small doesn’t mean that their service is poor. At the top of our list of companies, we find some smaller corporations. Being a small company does not default that company to providing poor service.
Non-profits and publicly traded companies typically are better choices. Whether because non-profits are subject to different rules and publicly traded companies rely more on public perception when determining their companies value, private companies typically perform worse when it comes to the service they provide for customers.
Lastly and most importantly, times change. Whether through market conditions or shifts in law. The quality of service might shift for better or worse among these competitors. Keeping your finger on the pulse might just be the difference in receiving the support necessary in a time of need or adding undo stress in an already stressful situation.
Comparing Scikit-LLM
When taking a look at the use of Scikit-LLM for sentiment analysis, we find some interesting findings.

If you look closely you’ll see a restructuring of where our reviews fall. My hypothesis is that our LLMs are ignoring the noise we as writers create and getting to the core of the issue. If we focus in on polarity we can quickly see this leap towards more polarizing reviews. We’ll be creating an average polarization difference (APD) to examine this.

Our negative reviews become more negative, and our positive reviews become more positive. This greater polarization may assist our sentiment analysis and create a more focused review. When we examine the polarization between the length of 90 and 45. We see a depreciating return when it comes to our smaller model. More likely than not there is a sweet spot and oversimplification of our review only hurts our sentiment analysis.
